

.png?width=344&height=101&name=Mask%20group%20(5).png)

User-generated content platforms, such as social media networks, forums, and online marketplaces, are essential parts of our digital landscape and drive AI development. While these platforms facilitate expression and interaction, they also need to ensure that shared content is safe, legal, and aligned with community guidelines.
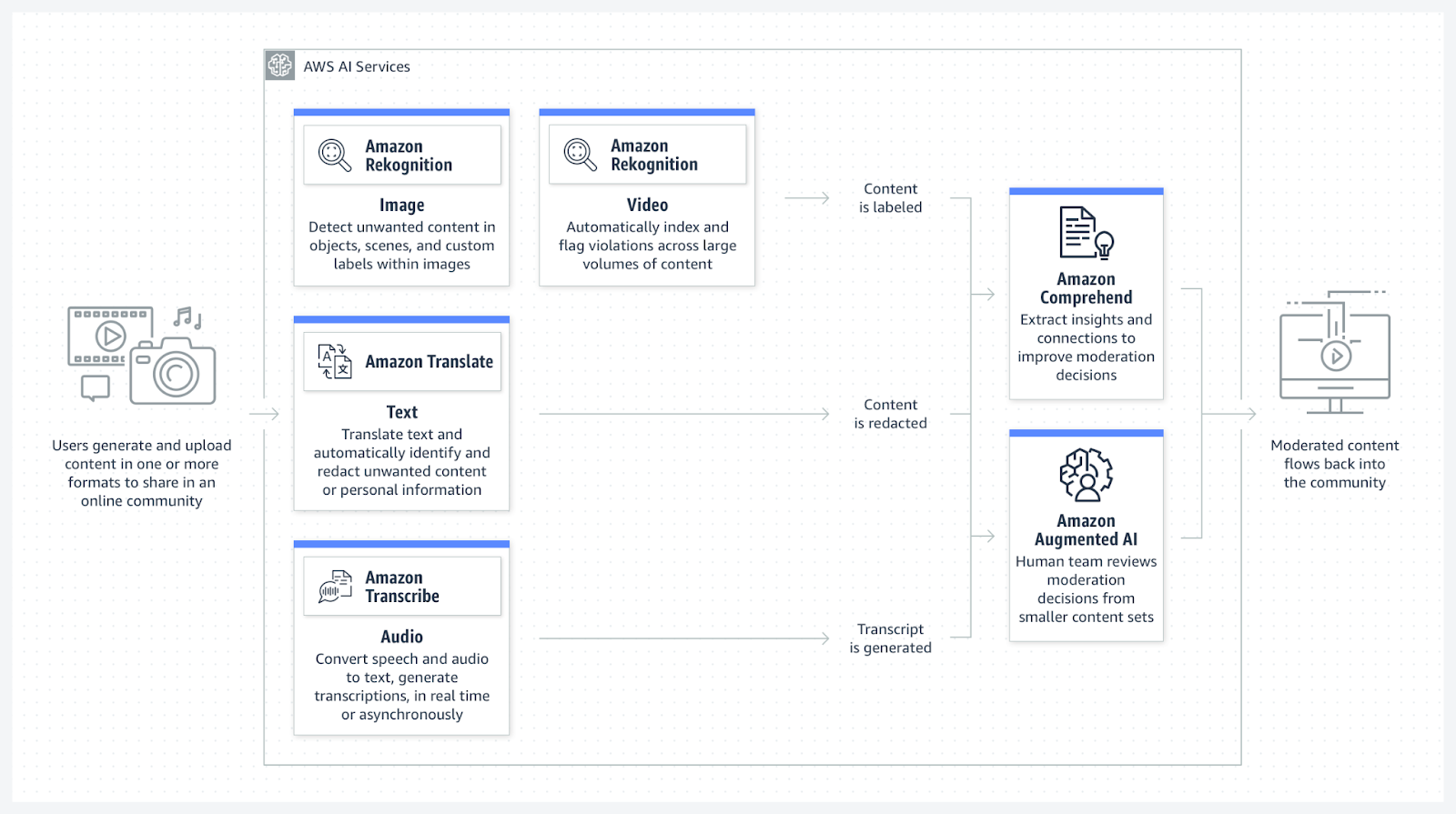
The Importance of Real-Time Content Moderation
Protecting Users:
Content moderation safeguards users from harmful, offensive, or illegal content, fostering a safer online environment.
Upholding Community Guidelines:
These platforms often have guidelines or terms of service that users must adhere to. Real-time moderation enforces these rules promptly.
Avoiding Legal Issues:
Failure to moderate content can lead to legal liabilities. Real-time moderation prevents the spread of infringing, defamatory, or illegal content.
Enhancing User Experience:
Moderation ensures users can engage without encountering disturbing or inappropriate content.
Real-Time Content Moderation in Python
To implement real-time content moderation, we can utilize machine learning models and libraries. Below, we provide Python code snippets using the 'nltk' and 'scikit-learn' libraries to build a basic moderation system. More advanced systems may employ deep learning techniques and custom datasets.
1. Install Dependencies:
pip install nltk scikit-learn |
2. Preprocess Text Data:
import nltkfrom nltk.tokenize import word_tokenizefrom nltk.corpus import stopwordsfrom nltk.stem import WordNetLemmatizerimport stringnltk.download('punkt')nltk.download('stopwords')nltk.download('wordnet')def preprocess_text(text): tokens = word_tokenize(text) tokens = [word.lower() for word in tokens if word.isalnum()] stop_words = set(stopwords.words('english')) tokens = [word for word in tokens if word not in stop_words] lemmatizer = WordNetLemmatizer() tokens = [lemmatizer.lemmatize(word) for word in tokens] return " ".join(tokens) |
3. Train a Moderation Model:
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import Pipelinedata = [ ("This is a safe post.", "safe"), ("Spammy links ahead!", "spam"), ("Hate speech is not allowed here.", "offensive"), # Add more examples as needed]X, y = zip(*data)X = [preprocess_text(text) for text in X]text_clf = Pipeline([ ('tfidf', TfidfVectorizer()), ('clf', MultinomialNB())])text_clf.fit(X, y) |
4. Real-Time Moderation:
def real_time_moderation(text): preprocessed_text = preprocess_text(text) predicted_class = text_clf.predict([preprocessed_text])[0] return predicted_class# Example usagetext = "This is a safe post. #Moderation"predicted_class = real_time_moderation(text)print(f"Predicted Class: {predicted_class}") |
Conclusion
Real-time content moderation is crucial for maintaining safe and compliant user-generated platforms. While this article provides a basic Python implementation using machine learning, real-world systems often require more complex models, extensive training datasets, and additional tools to handle multimedia content.
 As technology advances, content moderation will remain pivotal in ensuring the quality and safety of online platforms. Platform owners must invest in moderation solutions tailored to their specific needs and challenges.
As technology advances, content moderation will remain pivotal in ensuring the quality and safety of online platforms. Platform owners must invest in moderation solutions tailored to their specific needs and challenges.














