

.png?width=344&height=101&name=Mask%20group%20(5).png)

Transformer models have revolutionized the field of natural language processing (NLP), enabling groundbreaking achievements in tasks such as machine translation, sentiment analysis, and question-answering systems.
Among the many tools and libraries available for working with Transformer models, the Hugging Face Transformers library stands out as a popular choice for its ease of use and extensive model collection. In this article, we will walk through the workflow for training Transformer models using Hugging Face's library.
In this comprehensive guide, we will explore how to train these powerful models using Hugging Face – a popular library that has revolutionized the way we work with Transformers.
Whether you want to build state-of-the-art chatbots, translation systems, or sentiment analyzers, understanding how to effectively train Transformer models is essential. So fasten your seatbelts as we embark on an exciting journey through data preparation, tokenization, model configuration, training loops, and parameters - all with the help of Hugging Face.
By the end of this guide, you'll have a solid understanding of how to harness the full potential of Transformer models for your NLP projects. So let's get started and unlock the secrets behind successfully training Transformer models with Hugging Face!
What is a Transformer Model?
Transformer models have revolutionized the field of natural language processing (NLP) with their ability to capture long-range dependencies and contextual information in text. These models, introduced by Vaswani et al. in 2017, have become the go-to architecture for various NLP tasks.
Unlike traditional recurrent neural networks (RNNs) that process sequential data one step at a time, Transformers use self-attention mechanisms to weigh the importance of each word or token in a sentence. This allows them to consider all words simultaneously and capture global relationships within the text.
The key components of a Transformer model are its encoder and decoder layers. The encoder processes input sequences, while the decoder generates output sequences based on the encoded representations. Each layer consists of multiple attention heads that collectively learn different aspects of context.
One notable advantage of Transformers is their parallelizable nature, enabling efficient training on GPUs or distributed systems. Additionally, they can handle variable-length inputs without relying on fixed-size windows like RNNs do.
Transformer models have significantly improved performance across many NLP tasks, such as machine translation, question answering, sentiment analysis, and more. With an understanding of how these models work under the hood, we can now explore how to train them effectively using Hugging Face's powerful library!
#In this article, we will walk through the workflow for training Transformer models using Hugging Face's library.
Data Preparation
The journey to training a Transformer model starts with data. Whether you are creating a chatbot, a sentiment analysis model, or a language translation system, you need a high-quality dataset. Data collection and preprocessing are critical steps. You may need to clean and format your data, ensuring it is suitable for your specific task.
Tokenization
Transformers operate on fixed-length sequences of tokens. Tokenization is the process of splitting text into these tokens. Hugging Face provides efficient tokenizers for popular pre-trained models, such as BERT and GPT-2. Choose the appropriate tokenizer for your model and preprocess your data accordingly.
// Python source code
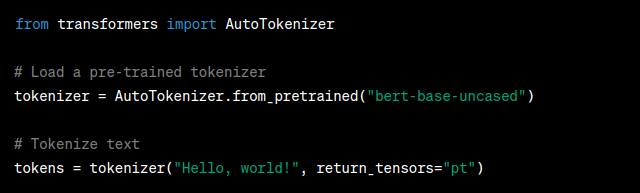
Model Configuration
Selecting the right model architecture is crucial. Hugging Face offers a wide range of pre-trained Transformer models, including BERT, GPT-2, and RoBERTa, for various NLP tasks. You can also create custom models using Hugging Face's model classes. Loading a pre-trained model is simple:
// Python source code
from transformers import AutoModelForSequenceClassification
# Load a pre-trained model
model AutoModelForSequenceClassification.from_pretrained("bert-base-uncased",num_labels=2)
Training Loop
The heart of model training is the training loop. Here, you feed batches of tokenized input data into your model, compute the loss, and update the model's weights using backpropagation. Hugging Face provides a ‘Trainer’ class that simplifies this process:
// Python source code
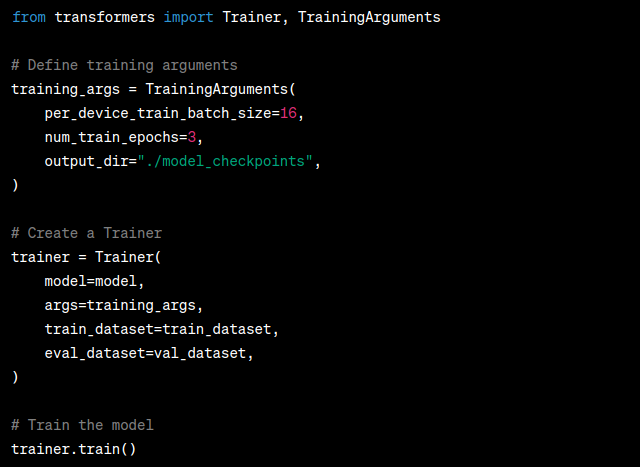
Training Parameters
Configuring hyperparameters such as batch size, learning rate, and optimizer is critical for successful training. These parameters significantly impact the training process and model performance. Experimentation and tuning may be required to find the best values for your task.
Fine-Tuning (Optional)
If you're using a pre-trained model, you may want to fine-tune it on your specific task. Fine-tuning involves training the model on your task-specific dataset to adapt it to your specific requirements. This step is especially valuable when your dataset is different from the data the model was originally trained on.
Monitoring and Evaluation
During training, monitor key metrics like loss, accuracy, and validation scores. Hugging Face's ‘Trainer’ logs these metrics for easy tracking. Use a validation dataset to evaluate your model's performance and adjust your training strategy accordingly.
Saving the Model
After successful training, save the model's weights and configuration. This allows you to reuse the trained model for inference, sharing, or further fine-tuning:
// Python source code
 Inference
Inference
Once your model is trained and saved, you can load it for inference on new data. This is where your model can be applied to real-world problems, making predictions or performing various NLP tasks.

Conclusion
Training Transformer models with Hugging Face's Transformers library is a powerful and accessible way to leverage state-of-the-art NLP capabilities. By following this workflow, you can create and train models for a wide range of tasks, from text classification to machine translation.
Remember that the success of your model often depends on the quality of your data, careful tuning of hyperparameters, and thoughtful evaluation. With practice and experimentation, you can harness the potential of these remarkable models for your specific NLP needs.















